supabrain
Context Allocation Across Time
The problem is not longer context. The problem is deciding what deserves context, when, and in what form.
Project overview
supabrain is a research project, not a product. It examines whether retrieval-augmented language-model agents need a per-memory utility signal that is distinct from the retrieval-similarity score the embedder already provides. The project ran across seven iterations between 2025 and 2026 — multi-resolution memory tiers, ELO-style hygiene, composite scoring, an abandoned real-corpus audit, query-conditional micro-tests, end-to-end evaluation on MemoryAgentBench, and finally a LoRA specialist trained on counterfactually ablated labels.
The project's primary contribution is methodological: counterfactual ablation as a per-memory utility signal that is non-circular with respect to cosine similarity by three structural arguments and is empirically separated from cosine across four large-scale runs. The signal makes it possible to ask "did this memory matter for this answer?" without the label-leakage failure modes that quietly trap most LLM-judge and rank-position baselines.
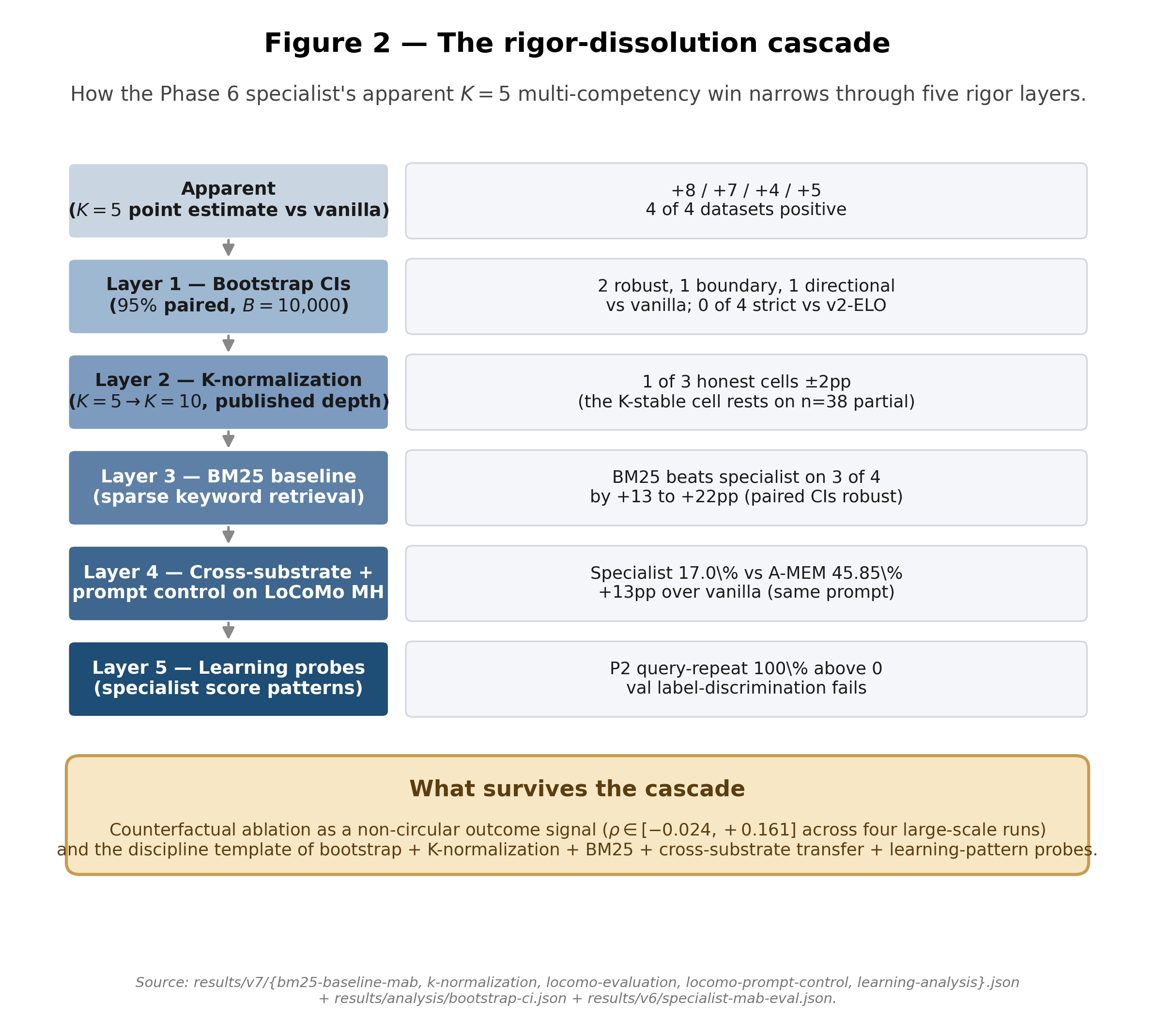
Phase 7 closed the build track (Pfad 1) under the project's pre-registered Rule C: all three triggers — MAB K=10 regression on 3/4 datasets, LoCoMo Multi-Hop F1 = 17.0% against A-MEM's published 45.85%, and a learning-pattern verdict of "MAB-K=5-locked surface-pattern detector" — fired independently. The broader hypothesis remains untested under operationalizations we did not run; the paper is the close-out of one operationalization, not a falsification of the thesis.
Paper
Counterfactual Ablation for Memory-Utility Evaluation:
A Pre-Registered Case Study in Specialist Re-ranking
Published on Zenodo, 1 June 2026 · CC-BY 4.0
![]()
Download PDF (23 pages) · Zenodo record · Code on GitHub
arXiv mirror: pending (cs.CL endorsement in progress).
Context allocation across time — not context length — is the central memory problem for retrieval-augmented language-model agents. The paper's methodological contribution is counterfactual ablation as a per-memory utility signal: remove each retrieved memory in turn and label it by the resulting change in answerer correctness. The construction is non-circular by three structural arguments, with Spearman correlations from −0.024 to +0.161 across four large-scale runs — three within-pipeline on MemoryAgentBench and LoCoMo, one substrate-independent on LoCoMo Multi-Hop whose confidence interval spans zero and which we treat as binding. We exercise the signal on one operationalization of the hypothesis that context-allocation requires per-memory utility distinct from cosine, and report a documented dissolution as the case study.
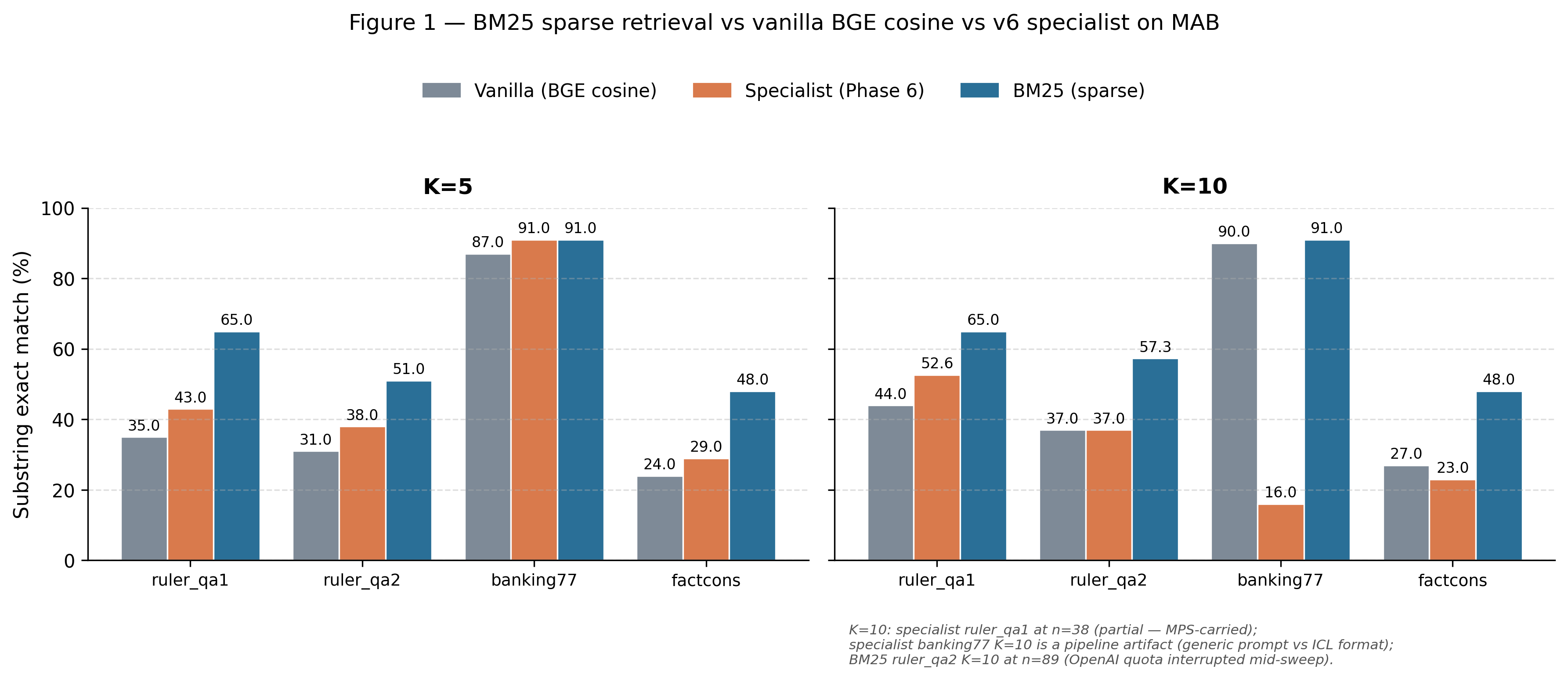
A 1.5B-parameter LoRA specialist trained on these labels produced point-estimate gains of +8/+7/+4/+5 substring-exact-match over vanilla retrieval at K = 5 on MemoryAgentBench. Five rigor layers tighten this result. Paired-bootstrap 95% confidence intervals leave two strictly significant cells. K-normalization to the published comparator depth leaves 1/4 datasets within ±2pp, on partial data. BM25 sparse retrieval beats the specialist by +13 to +22pp on three of four datasets, reframing the K = 5 gains as "less suboptimal than BGE cosine alone" rather than competitive. Cross-substrate transfer to LoCoMo Multi-Hop returns F1 17.0% against a published 45.85% (A-MEM, Xu et al. 2025), but a prompt-control shows the specialist contributes +13pp over vanilla cosine on the same prompt — the residual gap is pipeline-attributable, not total cross-substrate failure. Learning-pattern probes score memory-equals-query at 100% above zero and fail label discrimination on a held-out validation sample. What survives: counterfactual ablation as a non-circular outcome signal and the rigor-dissolution discipline with pre-registered ADRs anchored to public git history. The broader hypothesis remains untested under operationalizations we did not run.
Cite this work
Jürschik, M. (2026). Counterfactual Ablation for Memory-Utility Evaluation: A Pre-Registered Case Study in Specialist Re-ranking (v1.0.1). Zenodo. https://doi.org/10.5281/zenodo.20483675
BibTeX
@misc{jurschik2026counterfactual,
author = {J\"urschik, Max},
title = {Counterfactual Ablation for Memory-Utility
Evaluation: A Pre-Registered Case Study in
Specialist Re-ranking},
year = {2026},
publisher = {Zenodo},
version = {v1.0.1},
doi = {10.5281/zenodo.20483674},
url = {https://doi.org/10.5281/zenodo.20483674}
}
Methodology in brief
Memory-system evaluation in the published literature relies primarily on per-question task correctness on a downstream benchmark, which is gameable through configuration choices, and on LLM-judge scores of per-memory usefulness, which on extractive substrates collapse to topic match — what cosine similarity already measures. The project history catalogues three distinct forms of this outcome-signal circularity: synthetic-construction (utility assigned as an algebraic function of the similarity score), LLM-judge (a frozen judge that re-encodes cosine in prompt-disguise), and rank-position-synthesis (Win/Draw/Loss labels built from the rank at which a memory was retrieved). A specialist trained on labels from any of the three recovers cosine rather than learning beyond it.
Counterfactual ablation is one response. For each retrieved memory in a top-K context, recompute the answer with that memory removed and label the memory by the resulting change in correctness. The construction is non-circular with respect to the embedder's similarity score by three independent structural arguments (no similarity score in the label; no LLM judge; rank-independence within the retrieved set), and is empirically separated from cosine on every substrate where the signal applies. Across four large-scale runs — three within-pipeline on MemoryAgentBench and LoCoMo (n = 5,910; n = 1,000; n = 1,665), one substrate-independent on LoCoMo Multi-Hop (n = 175, ρ = −0.024 with CI spanning zero) — the rank correlation between counterfactual utility and BGE cosine ranged from −0.024 to +0.161. Rank-variance unexplained by linear cosine correlation was at least 96% in every row.
Iteration history
- v1 Multi-resolution memory tiers (L0/L1/L2). Tested compression as a path to utility-aware allocation. Synthetic-data win did not survive scrutiny.
- v2 ELO ratings + hygiene heuristics. Adaptive lift on synthetic data was −0.011 — ELO marginally worse than similarity-only. Synthetic-ground-truth circularity exposed.
- v3 Composite scoring (similarity × graph topology / ELO). Tested whether a structural signal from elsewhere helps. Multiplicative composite falsified; additive PageRank not better than baseline.
- v4 Real-corpus audit. Annotation protocol drafted; pilot run; budget gate hit. Phase abandoned; lessons folded into v4.6 + Phase 5.
- v4.6 Query-conditional micro-test. Established that per-query utility cannot be inferred from query-document similarity alone on real text.
- Phase 5 MemoryAgentBench evaluation. v2-ELO and v1 baselines run end-to-end across four priority datasets. Heuristics produce mixed results; the project commits to a learned specialist for Phase 6.
- Phase 6 LoRA specialist trained on counterfactual-ablation labels (n = 1,000 pairs). Point-estimate gains of +8/+7/+4/+5 SEM over vanilla at K = 5. Pre-registered AND-conjunction did not fire (val-F1 missed threshold); Pfad 2D primary recommendation stands.
- Phase 7 Scaled training data (n = 5,910); K-normalization; LoCoMo cross-substrate Rule D test; learning-pattern diagnostics. All three Rule C triggers fired independently. Pfad 1 build track closed. The rigor-dissolution arc IS the methodological contribution.
Code and data
The source repository at
github.com/ktdmax/supabrain
contains the full project history: planning documents, decision-rule ADRs
with timestamps anchored to commits, all generated training data, the LoRA
adapter weights from Phase 6, the four-rigor-layer evaluation outputs, the
BM25 and prompt-control measurements added in revision, and the figure
generation scripts. The pre-registration chain is auditable via
git log progress/v{6,7}/decisions.md.
Bulk training data and Modal-CUDA evaluation outputs are available on request; reach out at the contact address below.
Contact
- Max Jürschik
- Kill The Dragon GmbH, Vienna
- max@killthedragon.com